Eliminate duplicates in your ERP with a 'fuzzy match' algorithm
Oracle ERP + Oracle APEX + Jaro Winkler Algorithm

The solution below has proven successful at multiple Oracle ERP clients, so I am sharing it here in the hopes it inspires and helps others in a similar situation. Read on to learn how we:
eliminated customer duplicates with the introduction of an "approximate string matching" algorithm
simplified the customer-creation process by reducing the number of forms and clicks required by over 65% with the introduction of an Oracle APEX web app
The Problem Statement
A client ended up with many duplicate customer records, so many that they were running the Oracle ERP Customer Merge program every quarter. In merger and acquisition environments, it is common for the acquirer and acquired companies to share the same vendors and customers. This was certainly the case with a client. But how does the ERP, the source of record, end up with duplicate customers? Here's how:
- Oracle EBS does not enforce uniqueness in the customer name. For example, users were able to create "Cannon Industries" twice, each with a different customer account number:

- It also does not auto-enforce naming standards. For example, “Golfsmith Inc” versus "Golfsmith Inc.“ with a period versus "Golfsmith Incorporated" can all be created. In the screenshot below, the three entries below for "Southeastern Metal Products" represent the same customer and address, but to the ERP system, they represent three distinct customers:

The Oracle Customer form does provide the ability to search for a customer. However, it is optional, meaning the user can bypass the search and proceed directly to creating a duplicate customer without any alert or notification.
Even if the user were to perform a search, the search is not effective. For instance:
"Golfsmyth" with a "y" does not return existing customer “Golfsmith” with an "i"
"Golfsmith Inc" would not return existing customer "Golfsmith Incorporated" unless the user knew or remembered to search with a % wildcard operator after the word "Inc".
Notice the customer entries for "All Metals Fabricating" below. When creating a sales order, which one should an end user choose? Randomly choosing one over the other will split the customer revenue across the two records.

- Sitting down with end users revealed another obstacle. Users indicated the Customer form is overwhelming. They claimed that "editing a customer involves many nested tables and it’s easy to get lost. It feels safer to create a new customer than to edit an existing one".
Note the screenshot below - the customer "National Switchgear" has four active customer accounts in the ERP. Which one should the end user choose to transact with or update?
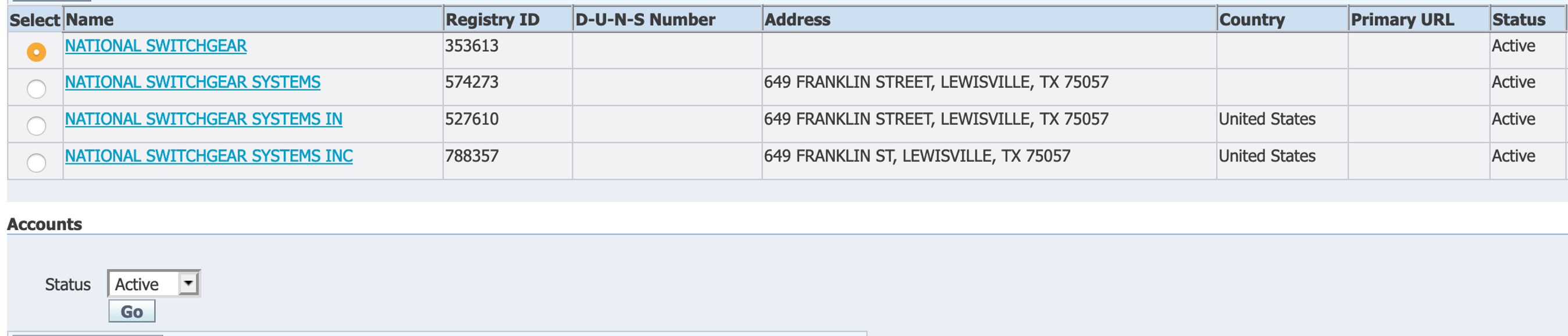
Conclusion: the complexity of the existing Customers Form and the shortcomings of the search feature to identify exact and near-duplicates all contributed to bloated Customer Masters across many clients.
The Approach
Addressing the five root causes above required a two-prong approach:
identify and display exact and near duplicates to the end user
simplify the view, edit and customer creation process in the existing Customer Master forms to address the fear and reluctance experienced by end users
Fuzzy Match
Oracle ERP documentation and Oracle Support websites offer methods to resolve duplicates, not prevent them, so we needed to think outside the box.
Note: Oracle EBS may offer near-duplicate search functionality with the license, use and configuration of the Data Quality Management and/or Customer Data Hub modules. These modules are not common; thus, this solution is applicable and popular with many Oracle EBS customers.
Oracle Cloud ERP also offers near-duplicate search functionality for customer search, but it may require additional licensing and tools such as Enterprise Data Quality, etc.
An Oracle search to resolve data duplicates lands on a blog by Richard Williams describing three helpful algorithms supported by the Oracle DB:
A Stack Overflow Page also describes “duplicate records that are similar but aren’t exact matches”.
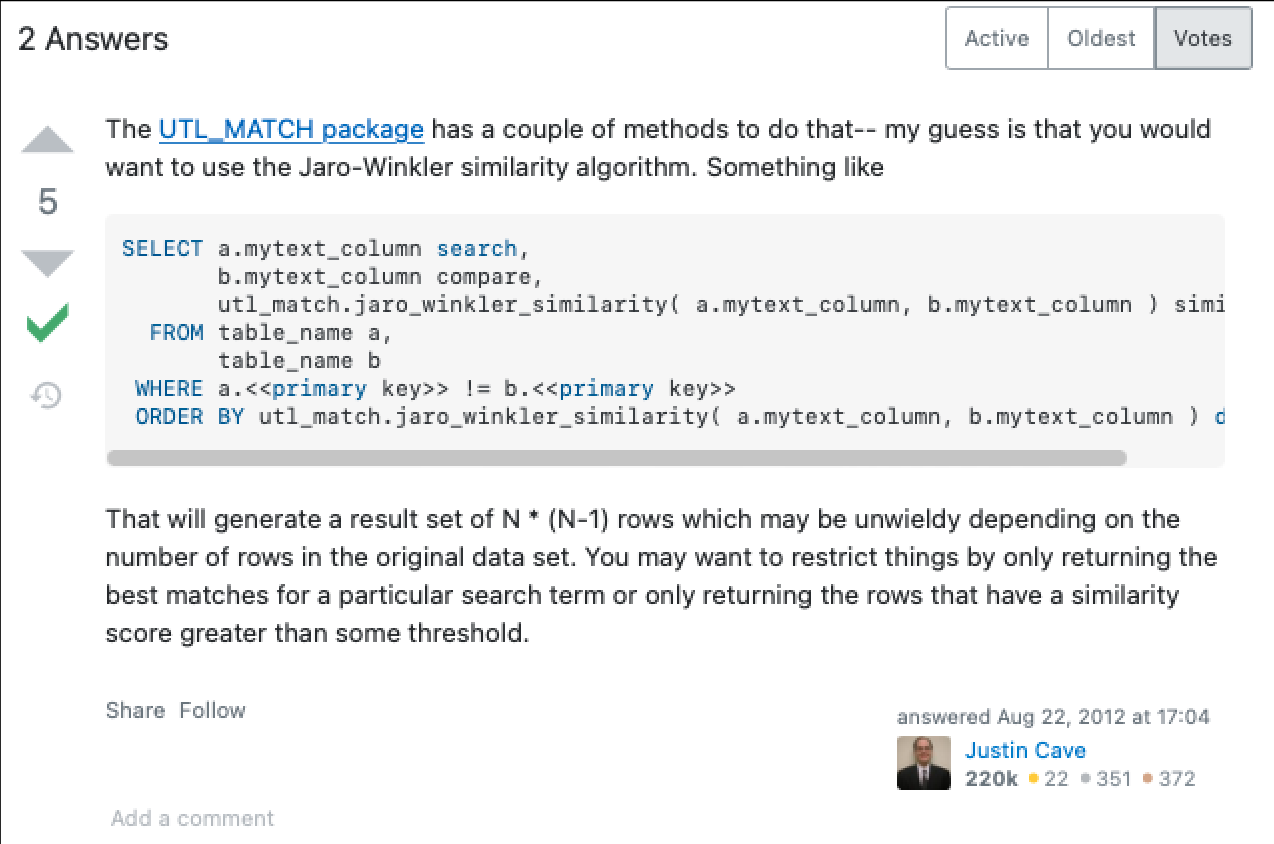
They both describe a Jaro-Winkler algorithm, which was developed by the US Census Department. The algorithm returns a matching score when performing a search between 0 and 100: 0 meaning no match, and 100 meaning a perfect match. It is considered a "Fuzzy search" algorithm because it finds patterns in strings (approximate string matching) for entries that are approximately similar but are not precisely the same - Bingo for our use case!
The Jaro-Winkler algorithm is implemented as a PL/SQL function in the Oracle Database:
UTL_MATCH.JARO_WINKLER_SIMILARITY (
s1 IN VARCHAR2,
s2 IN VARCHAR2)
RETURN PLS_INTEGER;
Running the function in our Oracle APEX test environment resulted in the following match scores when entering "GOLFSMITH" as a potential customer:
match score of 88% when compared to "Golfsmith Incorporated"
match score of 90% when compared to "Golfsmyth Inc." with a "Y"
match score of 92% when compared to "Golf Smith", spelled out as two words
and of course, a match score of 100% when compared to existing customer "Golfsmith"
See results in screenshot below:
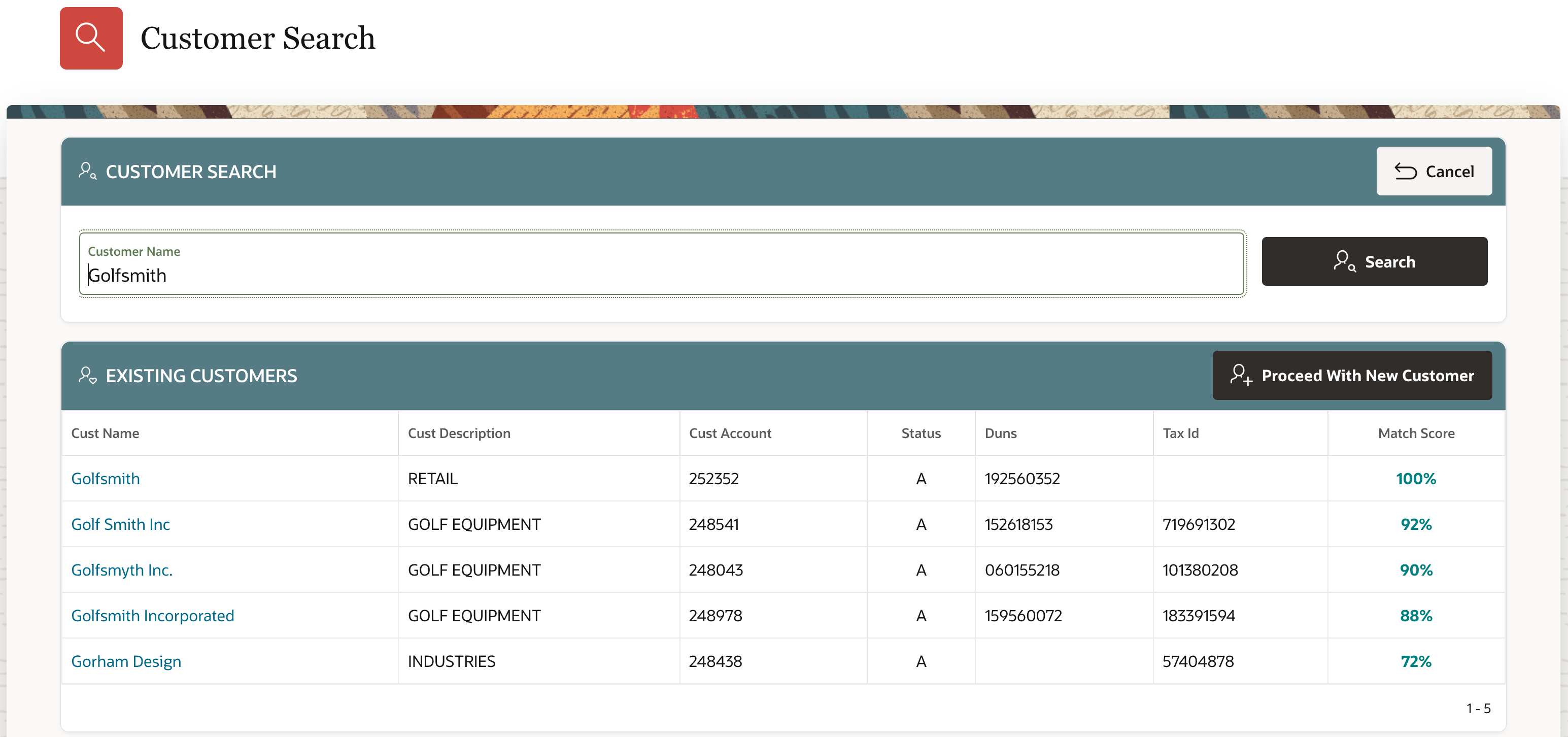
This approach elegantly addresses exact as well as near-duplicate conditions. It highlights instances of misspelled words, abbreviations, punctuation, etc. - something very hard to do with our customers' current functionality.
Here's a snippet of the exact code deployed to get the results above:
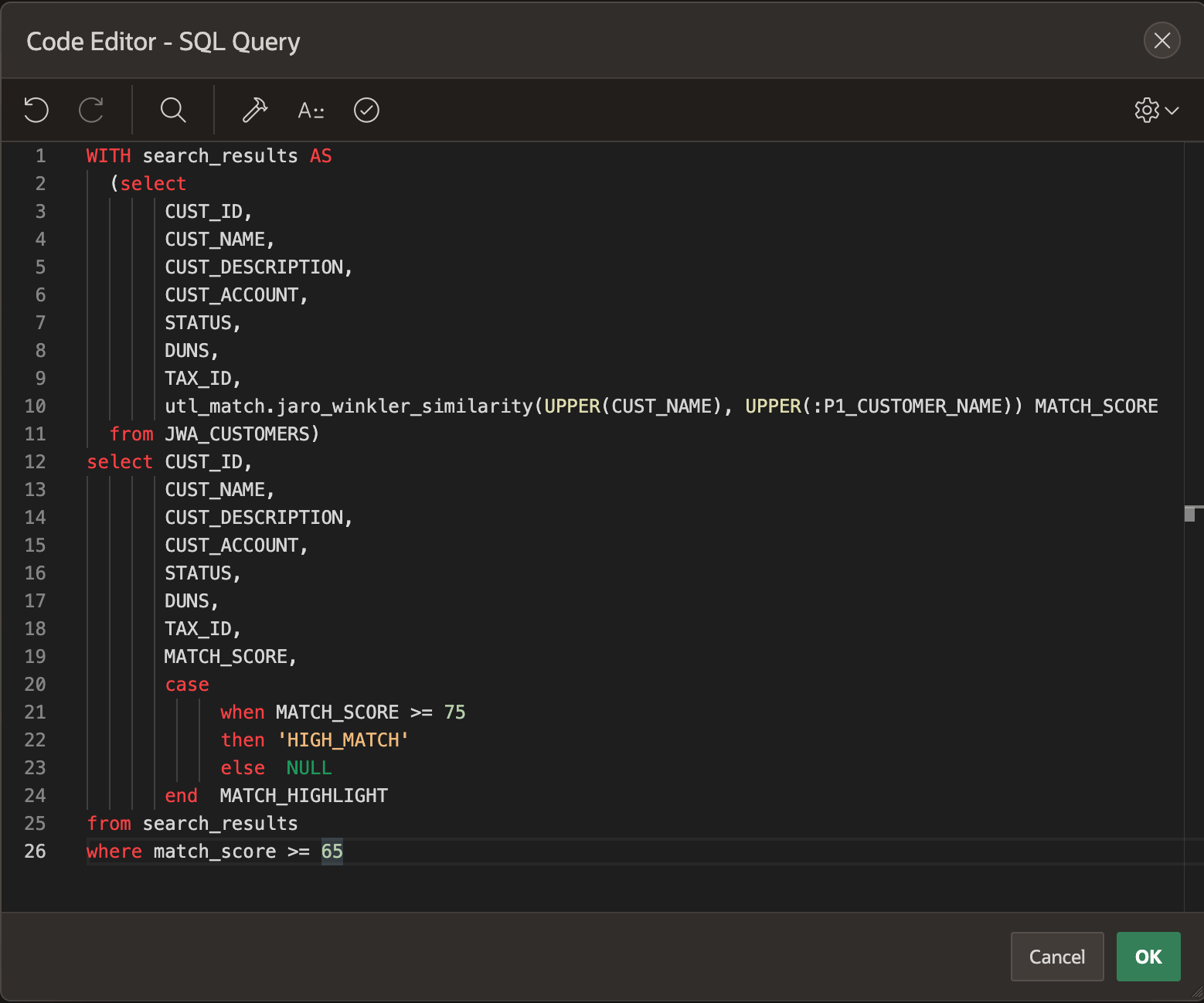
Here are a few things to call out:
Line 10: Here is where I call out the algorithm and assign it a column name of "MATCH_SCORE". UPPER function transforms both fields, the entered value and the value in the customer name column to uppercase to eliminate any potential case sensitivity.
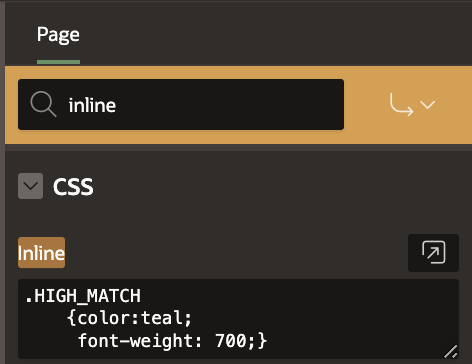
Line 20 - 24: I wanted match score results greater than 75 to be highlighted in blue, and thus, created a "HIGH_MATCH" function to do just that. The immediate screenshot below shows the CSS that turns match scores over 75 to blue. The CSS is captured in the Page section of the APEX web form.
Line 26: This line restricts results to display only those with a match score >= 65.
Simplifying the Customer Create Form
We concluded that replacing the multi-nested Oracle Customer forms with a one-page Oracle APEX web app would be safer and simpler. Here's how we went about it:
we gathered data and feedback from end users from multiple sites
we sat with users to observe each keyboard click, decision, pause and hesitation
we recorded user screens to further study every click, response and movement
This trove of data allowed us to design the APEX web app in such a way that:
every field was placed in the exact sequence needed.
every section, field and button could be activated with a keyboard click. Users would never have to lift their hand to move a mouse.
every potential click was evaluated and optimized. We used Dynamic Actions in Oracle APEX to control the tab order between fields.
In all, we optimized the customer creation page to just 10 essential fields. We replaced the multi-page, multi-nested, 60+ fields on the Oracle ERP Customers forms with a lightweight, fit-for-purpose Oracle APEX web page.
There are two additional design principles we incorporated:
- Design the Oracle APEX web apps in lock-step with EBS.
Using Oracle APEX, we utilized the Oracle EBS TCA public PL/SQL APIs to create and update customers. And because APEX is in the same database as Oracle EBS, we could query customer data directly from the customer tables. This integration minimized duplicity and ensured Oracle ERP remains the source of truth for all Customer records.
We also took advantage of EBS features such as lookups and address-style and tax-code formats so we didn't have to maintain them in two different places.
- Second design principle: when we built the web app, we built the customer creation process as a workflow to drive user behavior.
In the new APEX app, Customer Search was no longer optional. To create a new customer, users must type the customer name in a field and press submit. The algorithm would then return a listing of possible matches, along with a match score.
Each possible customer match was a link that, when clicked, displayed customer details via a pop-up with essential fields users rely on to determine if this is the customer they need
Suppose the customer is indeed the one the user needs. In this case, the user is allowed to perform edits as needed or, with the click of a button, automatically be navigated to the sales order form with that customer already populated on a new order
Otherwise, if the customer is not found, the user would select a button we named "Customer Not Found, Proceed With New Customer". By naming the button in this way, we force the user to review potential duplicates and acknowledge that a duplicate does not exist.
The Results
Performance
In Production EBS environments with up to 10,000 customers, it took no more than two seconds for the Jaro-Winkler algorithm to return search results. That's pretty impressive, considering the algorithm calculates and returns a match score for every customer record in the Customer Master.
If a client ever had over 100,000 customers, one could tailor the solution by introducing filters to limit the search to only customers of a specific profile class, country, or other classification. Such a filter would take careful consideration because you could end up filtering out a duplicate classified incorrectly. I'll share in my next blog tactics to improve performance and match score results by using filters, removing common business terms such as "The", "Inc.", "Incorporated", "LLC", and "Limited" from the search and introducing additional algorithms.
For example, Oracle DB also supports sound and phonetics-based matching via the SOUNDEX function. In our case, we are solving for misspellings and lack of auto-enforced standards such as "Inc." versus "Incorporated", and thus, "approximate string matching" addressed our use case well enough. However, laying such an algorithm on top of Jaro-Winkler should, in theory, improve the match score.
Business Impact
- Benefits of a clean Customer Master compound over time every time. Take a look at these wins:
Within months, duplicates trended to zero. Not having customers represented across multiple accounts improves the accuracy for each of the following:
Customer credit check - results in the improved vetting of customer creditworthiness
Customer sales - improves accuracy for trends and forecasting projections
Customer service - reps no longer have to guess which of the multiple accounts assigned to a customer to tag for a particular issue.
Customer marketing - improves reach for marketing campaigns and loyalty programs
Customer reporting - results in more accurate reporting for gross profit and operating margins
Customer sales rep compensation - results in more accurate calculations
The solution reduced the number of steps and clicks for creating and managing customers by over 65%. Per users, the solution also reduced anxiety as they could now rely on quantifiable search results.
And this one is my favorite: the solution was initially rolled out to just one division in the company. Word spread of this solution's success and we were asked to extend it to other divisions. There is no better measure of success than a repeat customer :)
Conclusion
The business impact spelled out above highlights the detrimental impact if your data, particularly your customer master, is not clean. This impact would also apply to vendors, products, raw materials, user logins, etc.
The beauty of this solution is that it not only replaces a reactive workaround (running the Customer Merge Process to address duplicates), it gets down to the root cause and addresses it.
Many methods, tools and algorithms are available to help tackle data duplicates in the enterprise. I hope the approach above inspires you with ideas and action to prevent duplicates in your environments too.